

Nell’ultimo numero di MeRi news abbiamo visto come sia importante, per controllare in anticipo gli attacchi della mosca delle olive (Bactrocera oleae), la data d’Inizio Infestazione (I.I.). Abbiamo anche visto che, per una stessa azienda (o per una stessa zona), le date d’I.I. da conoscere sono DUE: la data di I.I. attuale, cioè la data della prima ovideposizione della mosca nell’anno in corso e la data di I.I. media pluriennale, cioè la data media della prima ovideposizione nei dieci (meglio venti) anni precedenti.
Per una azienda, il modo più preciso e diretto per
determinare la data di I.I.
è di raccogliere, a partire dall’indurimento del nocciolo delle drupe (giugno),
100 olive ogni settimana, sezionarle e calcolare la percentuale di quelle con
uova o larve (o pupe) della mosca. Ed è questa la procedura seguita solitamente
dagli olivicoltori e (più spesso) dagli esperti delle loro associazioni.
Tuttavia, per essere utile, la procedura va ripetuta, nella stessa azienda, per
(ameno) dieci anni. Così, mentre per determinare la data di I.I. attuale basta applicare
la procedura nell’anno in corso, per avere la I.I.
media pluriennale ci vuole un periodo di tempo molto più lungo. E’
qui che casca l’asino. Considerando che il
rischio di attacco della mosca olearia in un certo anno è dato dall’anticipo della I.I. attuale sulla I.I. media pluriennale, se
non è nota la data di quest’ultima, la conoscenza della I.I.
attuale non ha un valore previsionale.
Per determinare la data di I.I.
media pluriennale si dovrebbe (o si sarebbe dovuto) mettere mano a
progetti decennali di osservazioni dell’I.I.
a livello di azienda (o di zona limitata); osservazioni eseguite sempre con la
stessa procedura in modo da dare dati (e date) confrontabili da cui calcolare
medie locali significative. Purtroppo, nel nostro Paese, risulta sempre più
difficile realizzare, in agricoltura, progetti di così ampio respiro (è più
facile organizzare mostre e fare spot pubblicitari). Molti progetti, dopo un
inizio promettente, sono stati prematuramente interrotti (e non per mancanza
d’idee e di prospettive). Come abbiamo visto nel post precedente. In generale,
la vera difficoltà per la previsione degli attacchi della mosca olearia non
risiede nella carenza di conoscenze scientifiche, ma nella mancanza di dati
adeguati per applicarle.
Fortunatamente, non tutti i progetti a lungo
termine in cui sono state determinate le date pluriennali d’I.I. della mosca sono stati
interrotti ed alcuni di essi sono ancora in corso (come, ad esempio, in Toscana).
Malgrado ciò, anche le zone sotto il loro controllo hanno subito un calo
significativo della produzione di olio a causa della mosca nel 2014. Segno che c’è
anche un altro asino che casca da un’altra parte. Dove?
L’esperienza dimostra che, nello stesso anno,
l’incidenza degli attacchi della mosca olearia sono distribuiti sul territorio
‘a macchie di leopardo’ e che, anche negli anni di infestazione generalizzata,
alcune zone sono colpite di più e altre di meno. Anche se la mosca vola, non
vola troppo lontano, né da tutte le parti nello stesso modo, e la sua densità
(e quindi il suo danno) varia sul territorio anche a piccola scala. Segno che,
oltre al volo, altri fattori ambientali contribuiscono a determinarne la
diffusione: microclima e vegetazione in primo luogo). In breve: l’entità degli
attacchi della mosca non varia solo temporalmente (da un anno all’altro, da un
mese all’altro), ma anche spazialmente (da un posto all’altro). Perciò, per un
controllo veramente efficace della Bactrocera, si pone il problema di una Rete di Monitoraggio dell’Infestazione
sul territorio. Dove analizzare le 100 olive e, soprattutto, quale deve essere
la distanza ottimale dei punti di monitoraggio?
Per affrontare questo problema, mi riferisco, ancora
una volta, al report ‘L’Olivicoltura
nel Lazio: la mosca delle olive nel territorio del Lazio’ frutto
della collaborazione tra il Laboratorio Entomologia della Scuola Sant’Anna di
Pisa (Istituto Scienze della Vita) e l’Agenzia Regionale ARSIAL della Regione Lazio. Nel Capitolo 6: ‘Discussione dei risultati’,
paragrafo: 6.2 ‘Ottimizzazione della rete di monitoraggio’, si suggerisce - in
base ad un’analisi geostatistica molto accurata - che, per aree olivate
omogenee è opportuno avere un punto di monitoraggio ogni 300 ha (ettari). E, dato
che negli anni del progetto (1999 – 2003), in 300 ha di aree olivate del Lazio
c’erano, in media, circa due punti di monitoraggio, si concludeva che la
Regione, per quanto riguarda il controllo della Bactrocera, ha “una buona
copertura del territorio”. Ora, però, se si considera che quei punti non sono
diminuiti significativamente negli ultimi 10 anni, è lecito chiedersi: come si
spiega il danno della mosca dello scorso anno anche nel Lazio?
Questa domanda non deve far pensare che una rete di
monitoraggio avrebbe evitato da sé l’attacco della mosca olearia, attacco che
dipende dalle condizioni climatiche e dalle caratteristiche biologiche
dell’insetto. Essa vuole ribadire che, per ridurre i danni, il problema è
quello di avere, in agricoltura, programmi
decennali di ricerca applicata (ad esempio per conoscere l’I.I. media pluriennale) nei
quali una rete di monitoraggio adeguata funzioni, senza interruzioni, da
strumento scientifico per stabilire il ruolo delle suddette condizioni
climatiche e caratteristiche biologiche nel
territorio considerato … proprio negli anni eccezionali. Perché la
conoscenza della Bactrocera non si fa soltanto nei laboratori universitari, ma soprattutto
in campo … e per questo servono tempi lunghi. E poi, se vogliamo passare dalla
mosca al suo danno (economico), mi pare opportuno riconoscere che questo vada
visto in riferimento all’azienda.
Facciamo due conti. La superficie olivata del Lazio
è di circa 110.000 ha e le aziende olivicole sono circa 86.000, dato che
110.000/86.000 = 1,28, una azienda olivicola della Regione gestisce in media
(molto) meno di 2 ha di oliveto. Pur assumendo che ogni azienda abbia 2 ha, un
punto di monitoraggio della Bactrocera ogni 300 ha dovrebbe ‘servire’ in media
150 aziende, se i punti di monitoraggio sono due, come nel Lazio, le aziende da
servire scendono a 75. Se questo numero può essere considerato buono per scopi
di programmazione regionale o provinciale (e a ciò si riferisce correttamente
il report L’Olivicoltura nel Lazio ),
esso è ancora troppo grande per poter parlare di controllo della Bactrocera
‘personalizzato’ per azienda. Per questo, è opportuno aumentare ulteriormente la
densità dei punti di monitoraggio dell’infestazione e scendere al di sotto
della densità di un punto ogni 100 ha,
cioè ogni km2 di superficie olivata (solo nelle zone ad elevata
densità olivicola). Una tale soluzione, che cura il danno della Bactrocera alla scala dell’azienda
olearia, richiede un’organizzazione specifica e finanziamenti adeguati. Di ciò
discuteremo nei prossimi numeri.
N.B. Il riferimento all’estensione dell’azienda
media è puramente indicativo, ciò che conta è la variabilità topografica e
microclimatica. Ma, sempre in media, considerando l’orografia tipica delle zone
olivicole italiane (e, in particolare del Lazio), in due aziende distanti tra
loro circa 1 km si dovranno distinguere, in media, due microclimi diversi e
quindi due giorni diversi d’Inizio Infestazione. Questa asserzione è sostenuta,
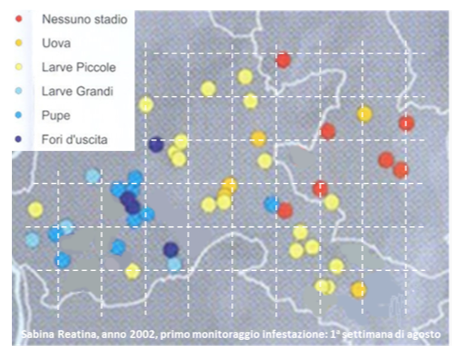
indirettamente, da una delle mappe riportate nella pubblicazione a cui ci
riferiamo. Dalla Tavola VIII abbiamo estratto i risultati del primo
campionamento delle olive. L’area rappresentata è all’incirca (20 x 20) km2
e mostra quanto sia variabile il grado d’infestazione iniziale sul territorio.
Abbiamo anche aggiunto un grigliato tratteggiato con maglia di circa 2 km per
mostrare che anche in un quadrato di 4 km2 (cioè 400 ha) il grado d’Infestazione
Iniziale (e quindi la data) I.I.
può variare, e di molto.
Si ringraziano gli autori della pubblicazione per il permesso di lavorare sulla loro mappa.
Maurizio Severini










